
The process to find abnormal and unusual values in a dataset is referred to as anomaly detection. It’s usually an unsupervised machine learning technique as rarely do we have labels for the observation, so most of the time, algorithms (algos for detecting anomalies) rely purely on features of the observations. There are two terms outlier detection and novelty detection that are often lumped together but do have distinct definitions.
- Outlier Detection: The process of identifying observations that deviate substantially from the rest.
- Novelty Detection: The process of identifying novel points by training a model with a data set that does not contain outliers. The model learns a boundary or boundaries and any points that reside outside of these boundaries are new and thus novel.
Implementing anomaly detection using scikit-learn
In scikit learn, anomaly detection algorithms are unsupervised learners. We will discuss two models for anomaly detection in scikit learn, one-class SVM and isolation forest. Both are unsupervised learning models with a similar interface; the essential methods are to fit/train the model with dataset X, then determine whether the observations in X are inliers or outliers and then use descision_function() to determine whether a point is an inlier/outlier. There are specific algorithms that are referred to as either outlier or novelty detection, these algorithms are discussed below:
One-class SVM
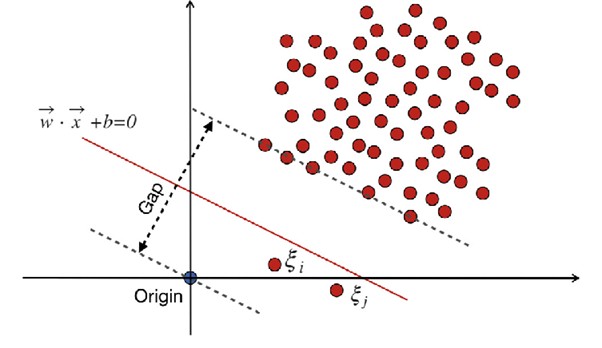
The support vector machine classifier can be tweaked to serve novelty detection applications, referred to as one-class support vector machines. This algorithm is a novelty detector because if we consider a binary classification situation in which all the points belong to the same class, it is assumed that there are no outliers.
The points are transformed to a higher dimensional space where you have the freedom to locate the origin of the coordinates. The algorithm’s task becomes to locate a hyperplane in the space that best separates the data from the origin. The catch is that hyperplane must go through the origin and should be located on the origin. The algorithm works by pushing as many of the vectors in the training set away from the origin in the feature space and it has to find the best balance between origin separation and margin violations from the training set. The image shown below illustrates an example of this algorithm. (The picture is in 2D, only for visualization purpose)
Isolation Forest
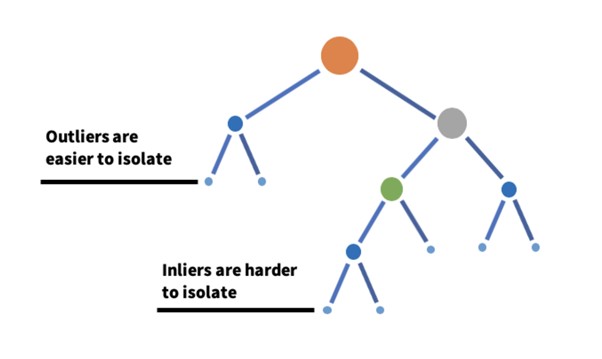
Isolation forests is an outlier detection algorithm that uses decision trees. The principle of this algorithm is that outliers are points with features that are considerably different from the rest of the data, the inliers. Consider a data set in p-dimensional space. The inliers will be closer together while the outliers will be farther apart. As we know, decision trees divide up p-dimensional space using orthogonal cuts.
Consider a decision tree that is constructed by making random cuts with randomly chosen features. The tree is allowed to grow until all points have been isolated. It will be easier to isolate or box in the outliers than the inliers. In other words, fewer splits are required to isolate outliers than the inliers, and outlier nodes will reside closer to the root node. The process of constructing a tree with random cuts is repeated to create an ensemble, hence the term forest in the algorithm’s name. While the algorithm could have adopted a more sophisticated manner to isolate points, making random splits is computationally cheap and averaging across all trees considers the multiple ways to isolate the data. The two key hyperparameters are estimators that give us the number of tresses uses in the ensemble, and contamination, which gives the fraction of outliers in the data set.
Comparison between one-class SVM and isolation forest
| One-Class SVM | Isolation Forest |
| One-class SVM is more sensitive to outliers. | Isolation is less sensitive compared to One-class SVM |
| One-class SVM is slower to train when compared to isolation forest. | Isolation forest is faster to train |
| One-class SVM is capable of adequately modelling multi-modal datasets. | Isolation forest is also capable of properly modelling multi-modal datasets. |
There are also other methods available in scikit-learn, which you can refer to at this website.
iSmile technologies offers free consultation with an expert, talk with an expert now




