


Automating Machine Learning workflows with SkLearn-Pandas.
Machine learning workflows include all the steps required to build machine learning models from raw data. These processes can be divided into the transformation and the training stages.
The transformation stage include the processes required to transform the raw data to features (feature engineering) while the training stage encapsulate the processes of using the features to build machine learning models.
The messiness of actual-world data typically makes feature engineering the most challenging and critical step in Machine Learning, especially when working with huge volumes of data streams from diverse sources. Feature engineering processes in such cases may include multiple, repetitive and distinct steps of mapping diverse raw data to machine learning features. An efficient way of dealing with such tasks is the use of feature pipelines.
Feature pipelines are frameworks that are utilized to automate the application of multiple, repetitive, and distinct feature engineering processes to raw data, sequentially and continuously.
When feature pipelines are designed, they can then be merged with machine learning algorithms to create Machine Learning pipelines which automates the machine learning workflows; from transforming the data to building estimators.
We would be using a simple dataset for an introductory example before having a more detailed example using the Titanic Dataset to practicalize how pipelines are utilized to efficiently and easily use raw data to build estimators.
We will be using an hypothetical “income” dataset that contains the ages, job titles, highest educational qualification and annual income of employees to demonstrate how pipelines are utilized to efficiently and easily transform raw data to build estimators. Our aim is to design and execute a machine learning pipeline to automate the data transformation and building processes using the SkLearn-Pandas library.
First, let’s take a look at the dataset.

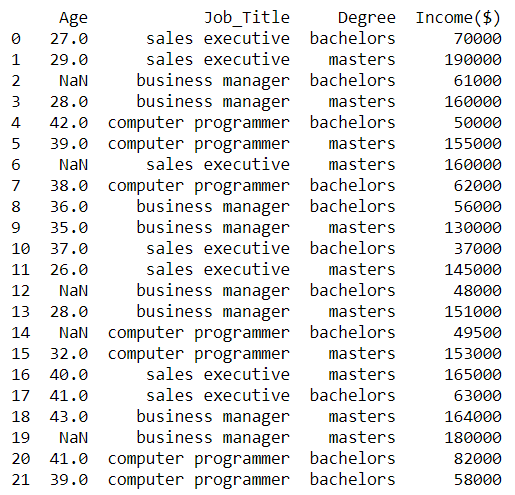
Table 1. Sample data of ages, job_title and qualification of employees.
We will need to apply certain transformations to this data before feeding it to an algorithm for training. The table below describes the required processes to build a model with this data.

Table 2. showing transformations to be applied to the data.
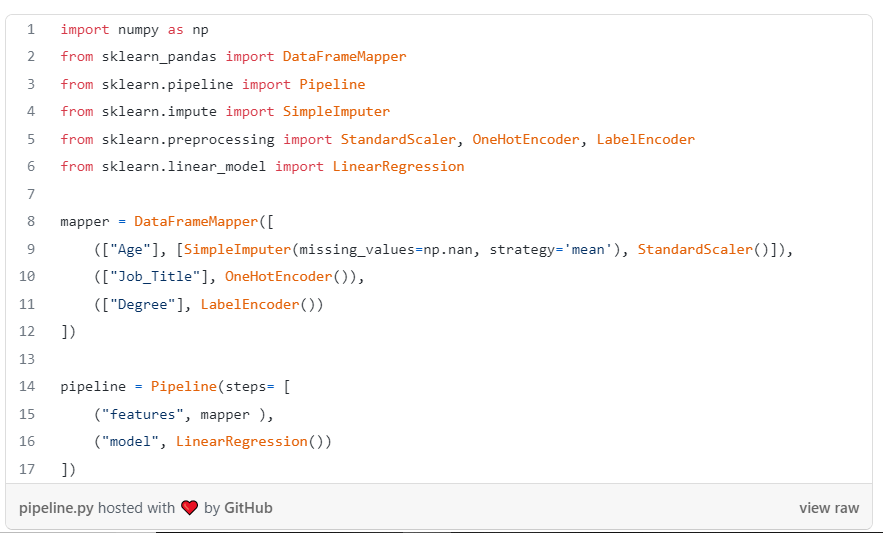
Next, We will define a machine learning pipeline to automate the application of these processes to the data. We will do this using SkLearn-Pandas’ DataFrameMapper and Sklearn’s preprocessing methods.
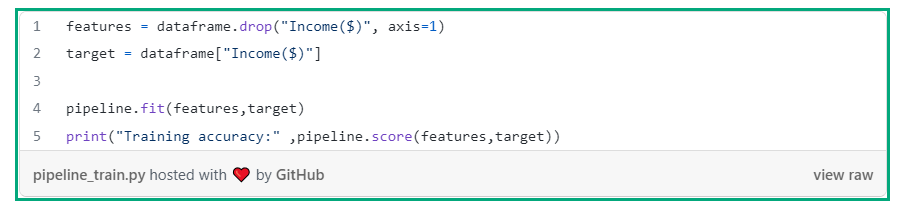
The defined pipeline can then be utilized to train the algorithm using the feature and target variables.
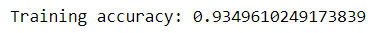
We have successfully developed a pipeline to automate the machine learning workflow such that it can also be used to transform other data streams with similar structures. You could also pass the pipeline to RandomSearchCV or GridSearchCV for hyperparameter tuning.
Summary:
Machine Learning pipelines are useful for automating the iterative processes of data transformation and building estimators. The pipelines offer efficient methods to automatically apply specific or diverse transformations to particular or numerous input features. Python libraries such as Sklearn and SkLearn-Pandas provide convenient methods to define and execute Machine Learning pipelines.
By Samuel Ozechi






