


In this paper, we will go through the basic scenario of migration from Hadoop on-premises to Microsoft Azure.
Firstly, let’s see, the benefits of migrating to Azure HDInsight:
- Secure and Complaint: Azure HDInsight implements encryption and integrates with Azure Active Directory to protect enterprise data assets.
- Easily Scalable: You can scale HDInsight workloads up and down on Azure. In addition to redistributing data, the platform rebalances workloads without interrupting work.
- Integration with other Azure services: Integration with other Azure services is easy with HDInsight, such as Azure Data Lake Storage Gen2, Azure SQL Database, and Azure Data Factory (ADF).
- Self-Healing processes and components: HDInsight monitors open-source components and infrastructure around the clock. Additionally, it automatically recovers critical failures such as unavailability of open-source components and nodes.
- Simplified version management: Azure HDInsight keeps Hadoop ecosystem components updated.
- Extensibility with custom tools: It is possible to extend the clusters of HDInsight with installed components. Furthermore, they are capable of integrating with other big data solutions.
Steps to Migrate
There are two main routes to moving your Hadoop data to Azure HDInsight:
- Transfer data over network with TLS
- Over Internet: Through the Internet, you can easily upload large amounts of data to Azure cloud storage. The Azure Storage Explorer, AzCopy, Azure PowerShell, etc. are all tools that can aid in this process.
- Express Route: In the Azure ExpressRoute service, users can create private connections between Microsoft data centres and infrastructure on premise or in a colocation facility. In addition to offering better security, reliability, and speeds than traditional Internet connections, ExpressRoute connections don’t go over the public Internet at all.
- Data Box Online Data Transfer: Both Data Box Gateway and Data Box Edge serve as online data transfer products and network storage gateways. The Data Box Edge is an on-premises network device that can transfer data to and from the Azure cloud using artificial intelligence-enabled edge compute. Data Box Gateway is a virtual appliance with storage gateway functionality.
- Shipping data offline: Devices such as Data Box Disk and Data Box Heavy let you transfer large data volumes to Azure when you cannot use a network. Devices for offline data transfers are shipped between the Azure datacentre and your organization. To help protect your data in transit, they use AES encryption. After upload, they perform a thorough sanitization process to remove your data from the device.
Type of data movement can be decided, depending on below factors:
- Data Size: Data size to be transferred
- Network: The amount of bandwidth available for data transfer in your environment.
- Transfer Frequency: Periodic or one-time data ingestion
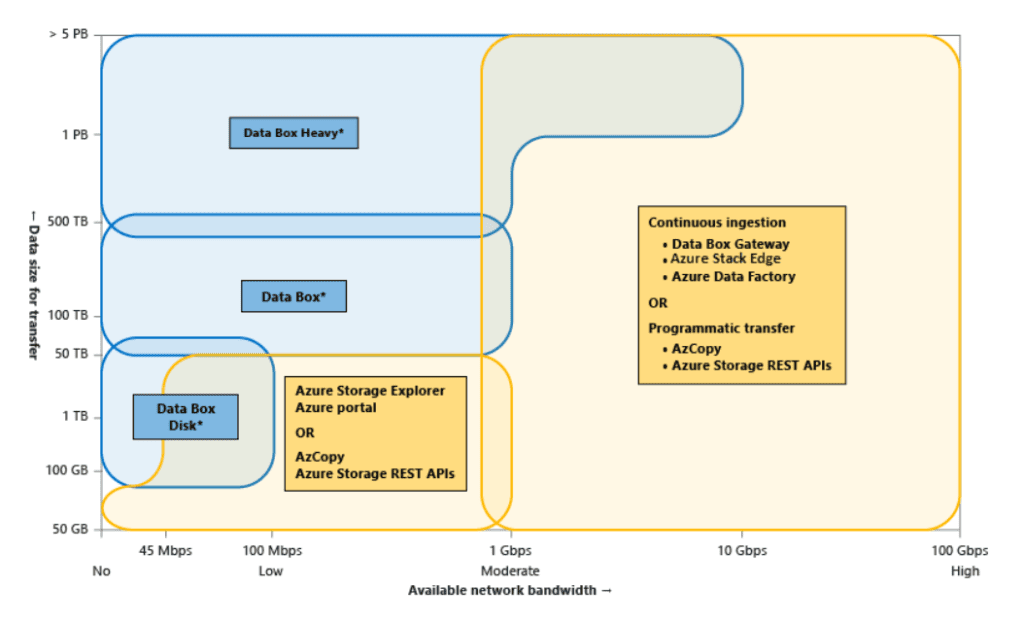
Based on bandwidth, data size, and transfer frequency, this image illustrates the guidelines for choosing Azure data transfer tools.
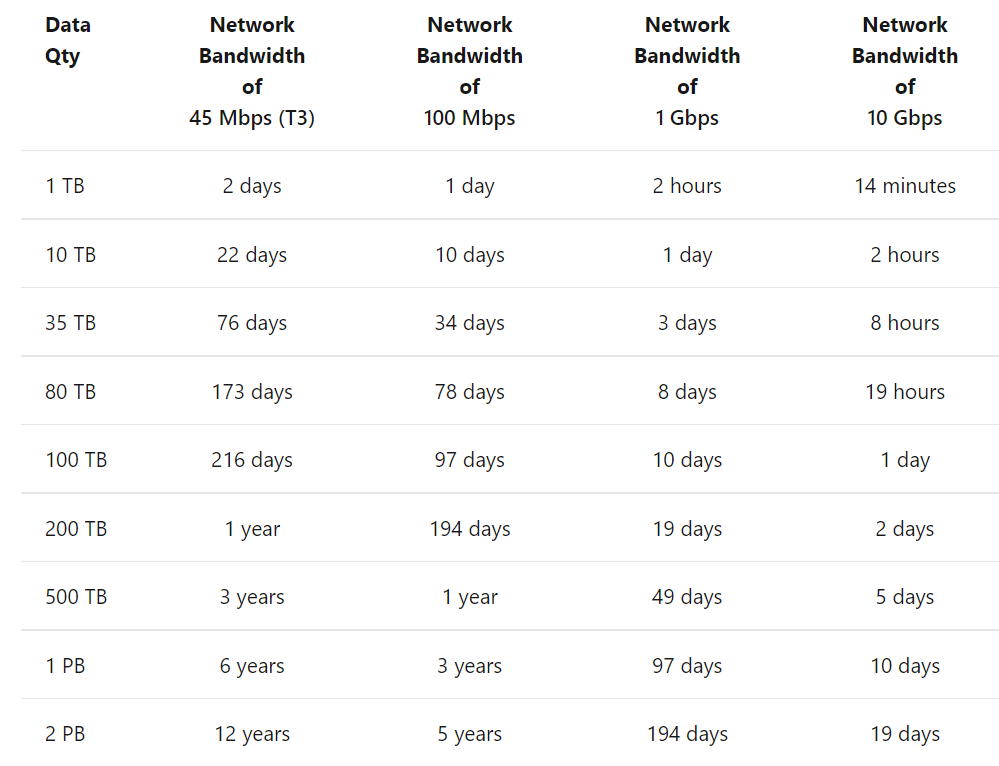
Based on data volume and bandwidth, the following table shows data transfer duration. Consider using a Data box if the migration is expected to take longer than three weeks.
A number of native Azure tools, such as Apache Hadoop DistCp, Azure Data Factory, and AzureCp, are available for data transfers. WANDisco is another tool that can be used for the same purpose. On-premises data can be transferred to Azure storage systems using Apache Kafka Mirrormaker and Apache Sqoop.
Apache Hadoop DistCp performance considerations
The DistCP project uses MapReduce Map jobs to handle data transfer, handle errors and recover from errors. For each Map task, Source files are assigned. It then copies all the files it has been assigned to the destination. You can improve the performance of DistCp using a number of techniques.
- Increase the number of Mappers:
In DistCp, tasks are created so that each one copies roughly the same amount of data. In DistCp, 20 mappers are used by default. With Distcp Mapper (‘m’ parameter at command line), data transfers can be parallelized, reducing their duration. While increasing the number of mappers, however, there are two factors to keep in mind:
- The lowest level of granularity of DistCp is a single file. By specifying more Mappers than source files, you are wasting cluster resources
- Mappers should be determined by considering the available Yarn memory on the cluster. A Yarn container is launched for every Map task. If no other heavy workloads are running on the cluster, the number of Mappers can be determined as follows: m = (number of worker nodes * YARN memory per worker node) / YARN container size. DistCp jobs can be limited to just a portion of YARN memory if other applications are using memory
- Use more than one DistCp job:
Use multiple DistCp jobs if the dataset to be moved is larger than 1 TB. By using multiple jobs, failures can be reduced. When a job fails, you need to restart only that particular job and not all of them.
- Consider splitting files:
When there are a few large files, consider splitting them into 256-MB chunks to increase concurrency with more Mappers.
- Increase the number of threads:
Check if increasing the -numListstatusThreads Parameters improve performance. The maximum value for this parameter is 40, and it controls the number of threads for building file listings.






