


How we can use Feature Engineering Techniques for Better Result
Feature engineering is one of the key steps in developing machine learning models. This involves any of the processes of selecting, aggregating, or extracting features from raw data with the aim of mapping the raw data to machine learning features.
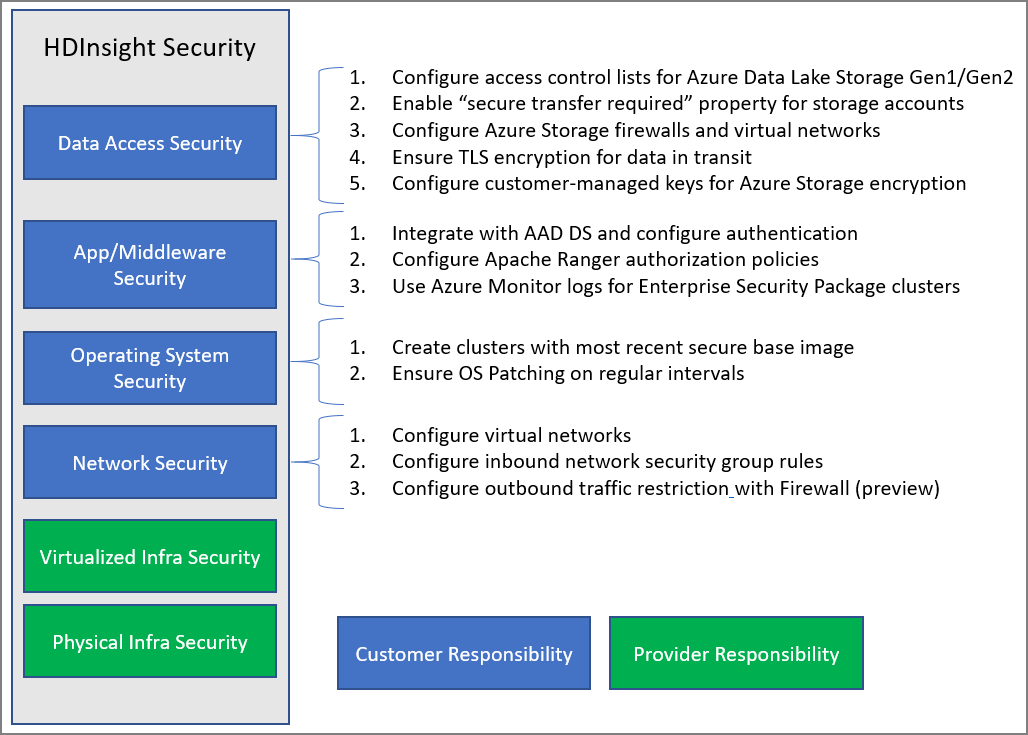
Fig. 1 Mapping raw data to machine learning features.
Numerical and non-numerical features are the two basic feature types that can be present in a data, these can be subdivided into discrete, continuous, categorical, text, image and temporal data.
The numerical and non-numerical columns of a Pandas dataframe that can be differentiated according to the datatypes of its columns.
Fig. 2. Getting numerical and non-numerical columns in a dataframe.
Numerical feature is a general term for the features of a dataset that hold numerical values that can be arranged in a logical order. It is often easier to work with numerical features in machine learning as numerical data formats are ingestible by machine learning algorithms.
Let’s look at some of the numerical features of the popular Housing price dataset.
Fig. 3. Sample Numerical columns of the Housing price dataset .
The numerical features of an input data are often expressed in different scales. Like in the example above, some features such as the “FullBath” and “HalfBath” have lower scales (<10) while other features such as “1stFlrSF” and “2ndFlrSF” have higher scales (>1000). It is often a good practice to standardize the scales of the input numerical data to have similar scales in order to avoid the algorithms from assigning more weights to the features with larger scales.
Numerical data can be scaled using Sklearn’s MinMax or Standard scalers. The MinMaxScaler scales the numerical data to have a range of 0 to 1 while StandardScaler scale the numerical data to a have a unit variance and mean of 0.
Fig. 4. Scaled numerical data using MinMaxScaler.
Non-numerical features include categorical and text data that are often encoded into numerals before being ingested into machine learning models.
Categorical data could be sometimes expressed as numbers but are not considered as numerical data as they show the relationship between different classes of a feature. Below is a dataframe of some categorical columns of the Housing price dataset.
Fig. 5. Sample columns of the Boston Housing dataset showing Categorical features.
To avoid making assumptions that categorical features that are expressed in numerical values are numerical features, its often preferable to one-hot encode categorical features as against label encoding them, which may trick machine learning algorithms to assume algebraic relationships among categories.
Unlike in label encoding where numerical values are simply assigned to represent respective categories, with one-hot encoding, each categorical value is converted into a new categorical column and assign a binary value of 1 or 0 to those columns. Each integer value is represented as a binary vector. This prevents the algorithms from assuming numerical ordering for categories (like assuming that a boy > girl if they are label encoded with 1 and 0 respectively) thereby improving the performance of the model.
Following the previous example, below is subpart of sample categorial columns from the Housing price dataset.

Fig 6. Sample categorical columns of Boston Housing dataset
Rather than represent each of the categories in these columns with a numerical value (label encoding) for model ingestion, we could one-hot encode the features in the dataframe, such that the presence of a category in a datapoint is denoted with 1 while absence is denoted with zero. This can be easily done using using Scikit Learn’s oneHotEncoder.

Fig 7. One hot encoded features of the categorical column.
The result are one-hot encoded features that could be ingested into models for efficient performance. Notice that the output dataframe now contains more columns which have numerical values (1.0, 0.0) that are representative of the presence or absence of that category in each datapoint. Thus each column has been expanded into separate columns according to the number of categories in the column.
For text data, it is necessary to represent them as numerical values which is recognized by machine learning algorithms through vectorization. Some common text vectorization techniques are word count, term frequency–inverse document frequency (TF–IDF) and word embeddings.
Word count is a simple vectorization technique of representing text data as numerical values according to the frequency of their occurrence in the data.
Consider a list of texts below for example:
To vectorize the text data above using the word count technique, a sparse matrix is formed by recording the number of times each word appears in the text data. This can be achieved using Scikit Learn’s CountVectorizer.

Fig. 8. Word count for the text data
The output shows the vectorized features of the input text data which can now be ingested into algorithms. While this technique achieves the vectorization purpose, it is suboptimal for machine learning algorithms as it only focuses on the frequency of words in the data. A better alternative approach is the Term Frequency–Inverse Document Frequency (TF–IDF) method that focuses on both the frequency of the words and their importance in the text data.
In TF-IDF, the importance of each word in a text data is inferred by the inverse document frequency (IDF) of the word. The inverse document frequency is a statistical measure that evaluates how relevant a word is to a document in a collection of documents. The IDF for each word is calculated thus:
An important aspect of the TF-IDF approach is that it assigns low scores to words that are either abundant or rare in the text data as it assumes that they are of less importance in finding patterns in the data. This is usually helpful in building efficient models as common words such as ‘The’, ‘is’, ‘are’, ‘of’ and rare words are mostly of little or no help in real time pattern recognition. Sklearn’s TfidfVectorizer is useful to easily vectorize text data in this way.

Fig. 9. Dataframe showing the inverse document frequencies for the words in the data
The output shows that the text data is vectorized according to the TF-IDF values of the words and can be then ingested into algorithms for learning. The disadvantage of the TD-IDF approach is that it doesn’t take account of words which share similar meaning; nevertheless, it’s still a good fit for processing text data.
A common technique of improving the performance of machine learning models through feature engineering is by deriving new features from existing features. This can be done mathematically by combining the input features in some way, thereby transforming the input features.
In the Housing price dataset example for instance, square feet per room or Total rooms number of rooms in the house features are often more reflective and indicative on the target price of the house than individual features such as the number of bedrooms, bathrooms etc. In cases where such important features are not present in the data, they could be derived by mathematically combining the input features.
Missing data are often a problem in machine learning. Dealing with missing data is another important aspect of feature engineering. This usually involves dropping data points with missing values altogether, replacing them by utilizing any of the measures of central tendency (mean, median or mode) or by matrix completion.
Summary: Feature engineering involves the processes of mapping raw data to machine learning features. The processes of feature engineering depend on the types of the data. common feature engineering processes includes scaling numerical data, label or one-hot encoding categorical data, vectorizing text data, deriving new features and handling missing data. Proper feature engineering helps to make raw data suitable for ingestion into machine learning models and improves the performance of machine learning models.






