

Data volumes keep increasing at an unprecedented rate, exploding from terabytes to petabytes and sometimes something larger. Scalability and price make it complex for traditional on-premises data analytics approaches to handle these data volumes.
As a result, most companies take all their data from various silos and aggregate it in a specified location before performing analytics and ML directly on top of that data. Our data Platform is designed to remix this process in a simplified manner, thereby reducing costs and transferring the traditional on-premises resources to the cloud in a manner that gives our customers an advantage with the following resulting attributes;
- Reduce data silos to the barest minimum.
- Build a personified customer view.
- Design your tech architecture and,
- Improve one platform for privacy.
DATA PLATFORM COMPONENTS
With amazing components to help simplify the process of data engineering to the last phase, which is visualization, we simplify the process of data engineering, thereby giving you more for little with the following components and attributes as illustrated in the image below:
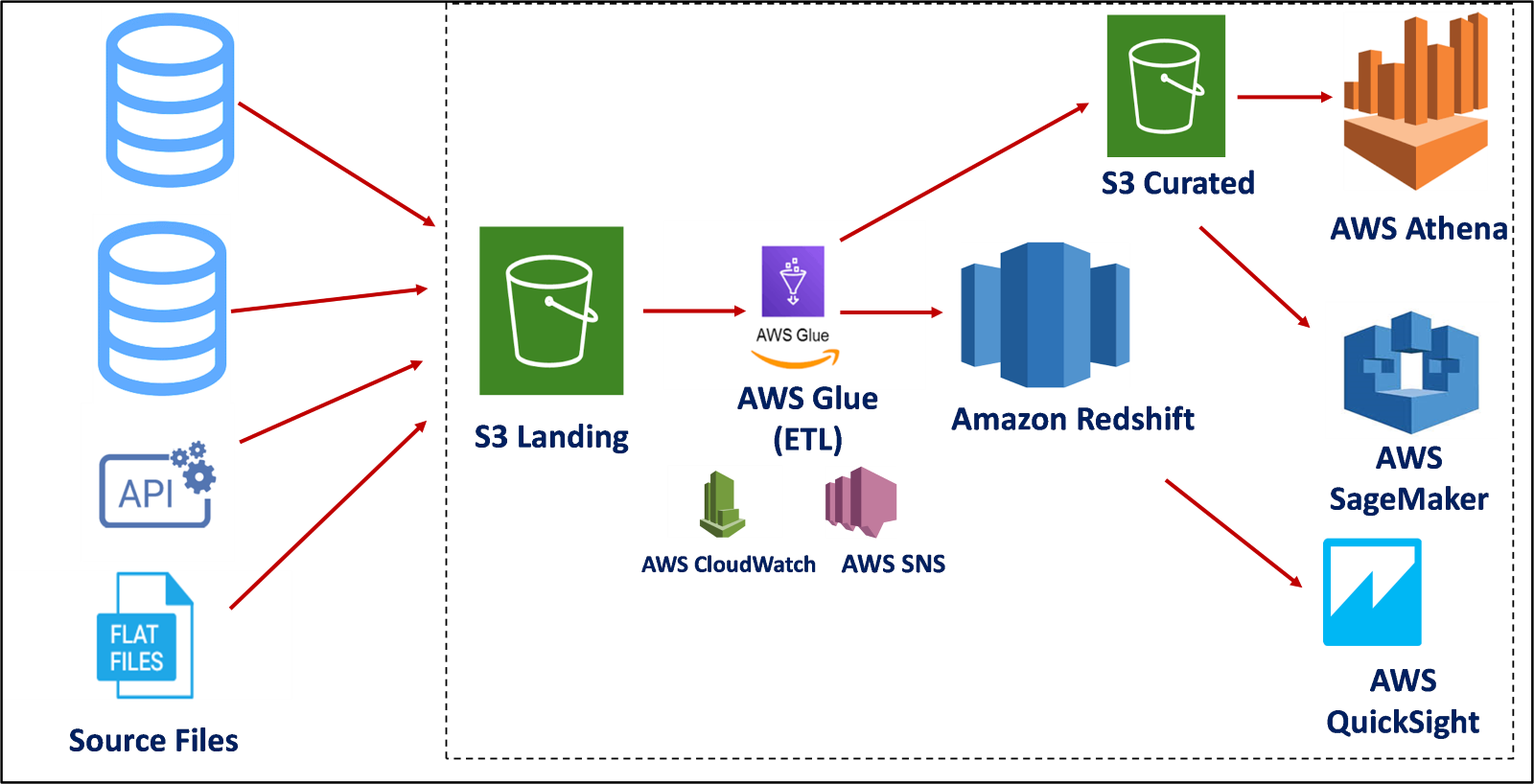
A. Data Ingestion
The data lake does the work of providing a bucket for storing, extracting, and loading the data for utilization using scripts to transform. The following are the steps to build a glue resource for data ingestion:
1. State your provider

2. Create policies for the bucket to be able to perform the required tasks

3. Build a bucket for storing data in CSV format

4. Build a Glue Crawler: A crawler can crawl multiple data stores in a single run. Upon completion, the crawler creates or updates one or more tables in your Data Catalog with the path to the bucket you created.
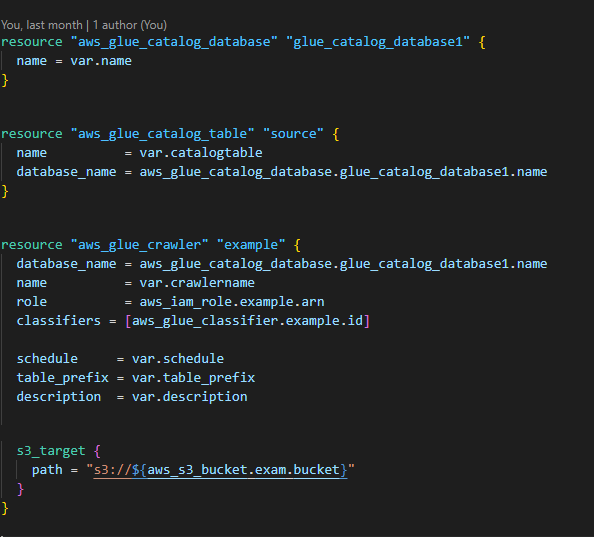
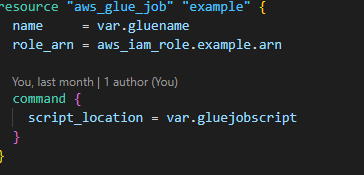
5. Build an ETL job with scripts to Extract the data, Load the data and extract the data into a warehouse for analyzing.
6. Build a Crawler classifier to define metadata tables.
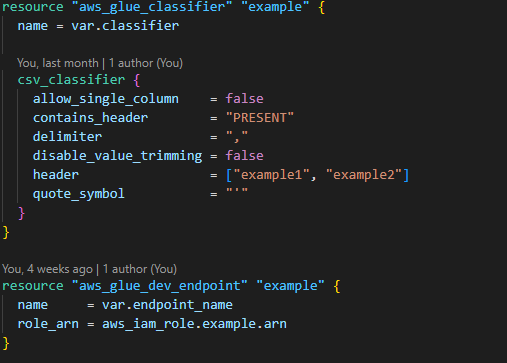
B. Data Warehousing
A data warehouse is a central repository of information that can be analyzed to make more informed decisions. Data flows into a data warehouse from transactional systems, relational databases, and other sources, typically on a regular cadence.
The following are steps taken to build Amazon Redshift resources for Data Warehousing
1. Build a resource stating the role of Redshift
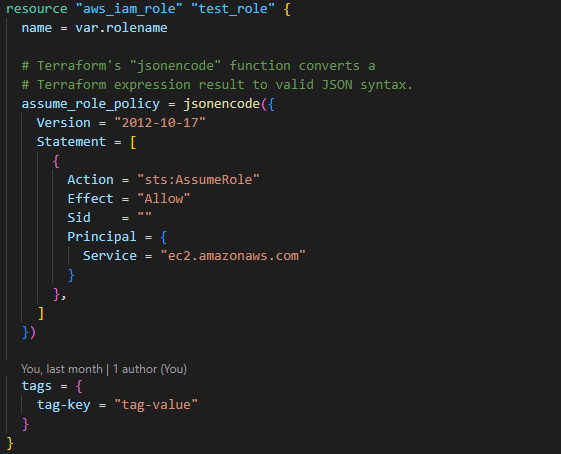
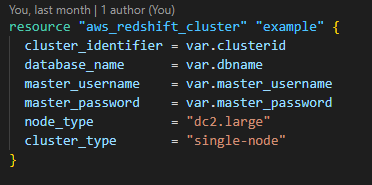
2. Build a Redshift cluster resource to provide the warehouse ability to query large volumes of data at speed and scale linearly to cater for data growth.
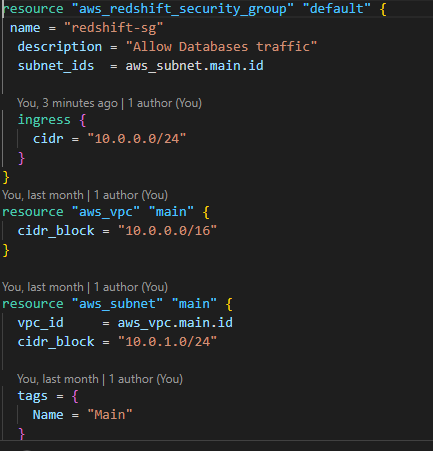
3. Attach a security group to the warehouse thereby providing some level of security to the transformed data.
C. Data Modelling
Data modeling creates a visual representation of either a whole information system or parts to communicate connections between data points and structures. The goal is to illustrate the types of data used and stored within the system, the relationships among them, how the data can be grouped and organized, and its formats and attributes.
After storing, extracting, loading, transforming, and storing our data, there is a need to model for the final consumer to have a pictorial glimpse of every process the project underwent. As such, AWS Athena and Quicksight resources need to be built to perform these operations using the steps below:
1. Create a bucket to store and another bucket with access to be able to get built resources from others
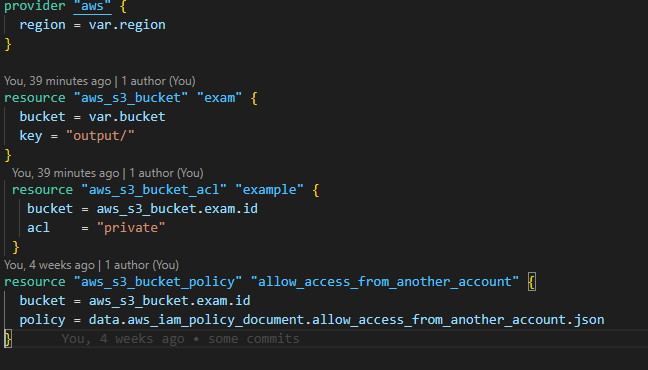
2. Create a Policy to cater for bucket-sharing
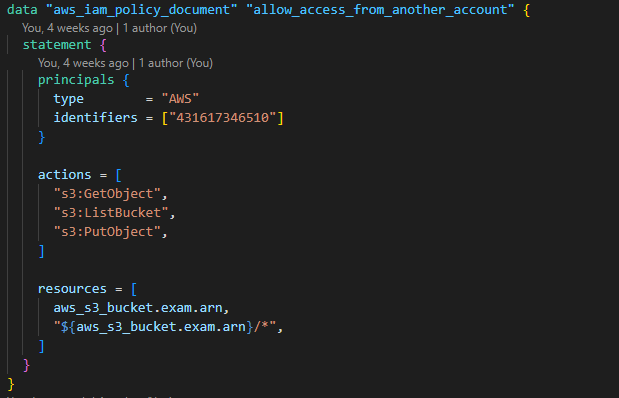
3. Create an Athena data catalog with the necessary policies to make it run.
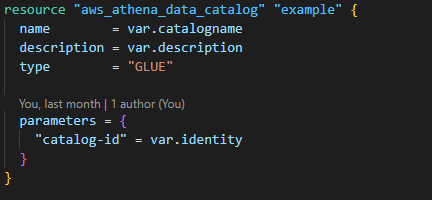
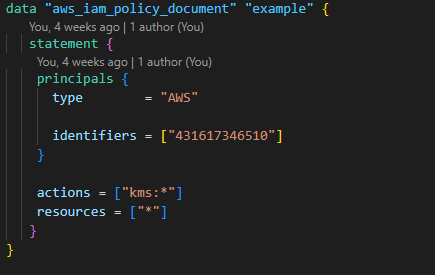
4. Create an Athena workgroup to show the history of queries and link them to quick sight.
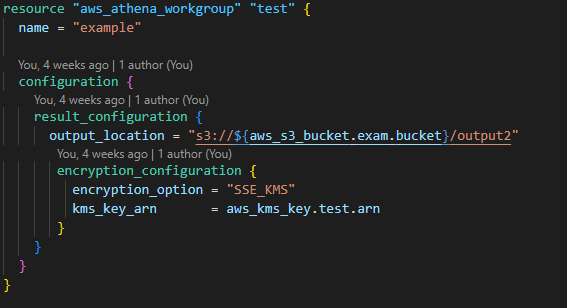
5. Create a database structure to query your transformed resource.
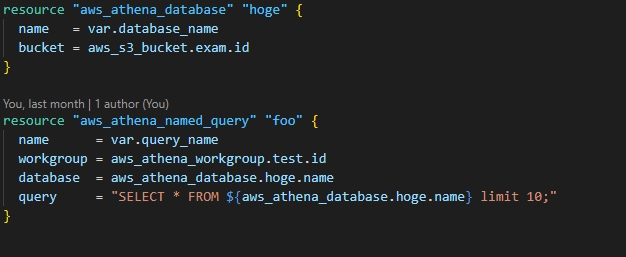
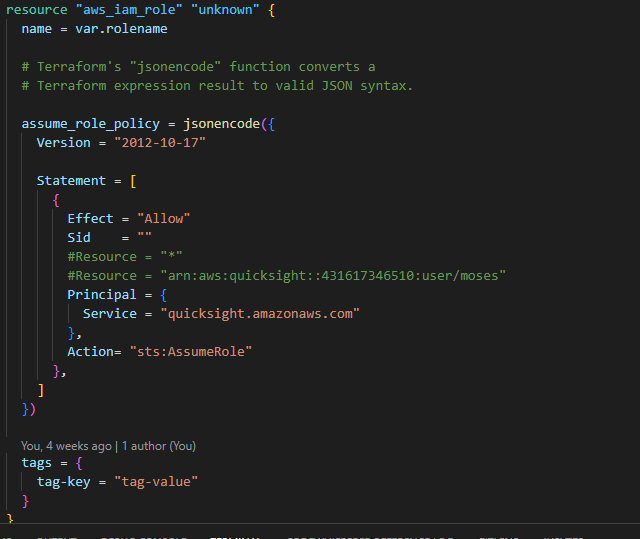
6. Create a Quicksight role to direct the user to visualization of your data.
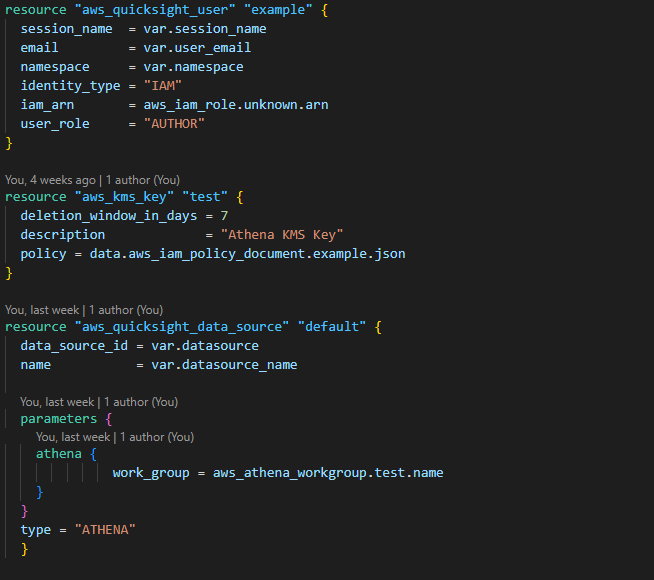
7. Create a Quicksight user with the necessary permissions.
Staging the Resources
1. Initializing the resources: This entails staging the resources to be built on the cloud by initializing them and getting them prepared to be deployed. This process checks for every dependency required and confirms if they are deployable.
2. Planning the Resources: To deploy infrastructure in aws, there has to be a structure stating what infrastructure is in aws, there has to be a structure stating what is to be deployed, and several dependencies and rules are needed. A pictorial review is found below.
Conclusion
With growing data analytics needs, your business may be able to benefit from the offerings AWS has in the world of data platforms. Between higher performance, lower cost, and more flexibility, there is a multitude of ways you stand to benefit from implementing our data platform solution. For more information, Get Your Free Consultation.
Cloud Engineer
Gabriel Chutuape
A technology enthusiast passionate about automation, Gabriel Chutuape is a Cloud Engineer at ISmile Technologies. He’s part of the ISmile Technologies Cloud enablement team that help customers to design/solution/project engineering, integrating and implementing infrastructure technologies & services.
CLOUD ENGINEER INTERN
Boriowo Moses
Moses is a Tech Enthusiast, with demonstrated exposure of working in Information Technology and with the Telecommunications industry. His skills are centered in ensuring timely, safe and secured solution efficiencies among businesses.






