


Elasticsearch is a powerful tool for storing, searching and analyzing large amounts of data. It is built on top of Apache Lucene, a high-performance text search engine library. In this blog post, we will discuss how to ingest data into Elasticsearch clusters. We will cover the different methods available for importing data and best practices for optimizing data ingestion performance.
1. Understanding the Elasticsearch Data Model
Before we dive into the specifics of data ingestion, it’s essential to understand the Elasticsearch data model. Elasticsearch stores data in documents, which are organized into indices. Each index can have one or more types, and each type can have one or more documents. The structure of the documents is defined by a mapping, which specifies the fields and their data types.
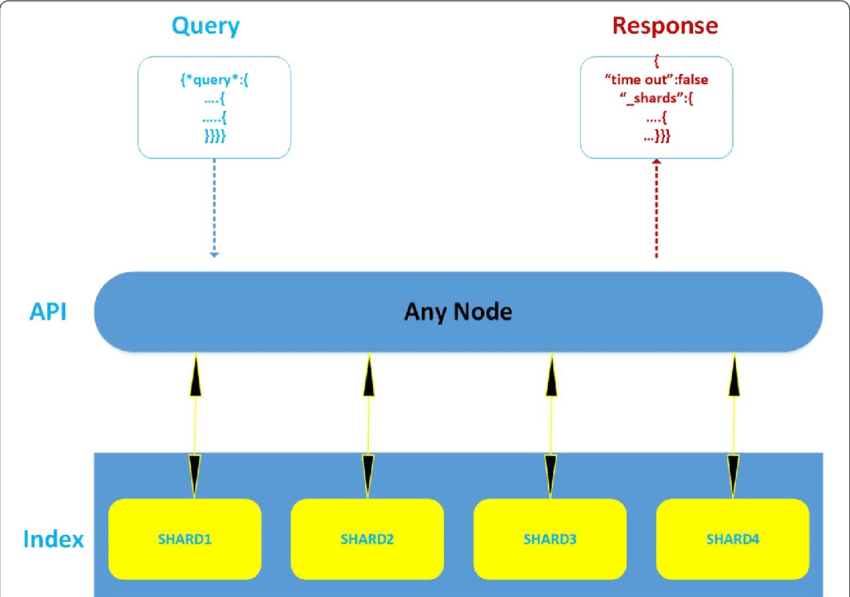
2. Importing Data Using the Elasticsearch API
The most common way to ingest data into Elasticsearch is using the Elasticsearch API. The API provides a set of endpoints for creating, updating, and deleting documents and for searching and aggregating data. To import data, you can use the index API to create or update a document or the bulk API to create, update, or delete multiple documents at once.
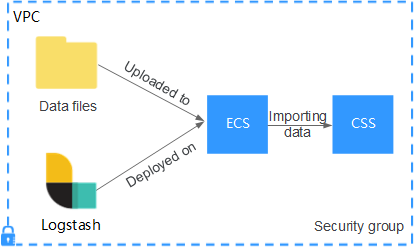
3. Importing Data Using Logstash
Another way to ingest data into Elasticsearch is using Logstash, a data processing pipeline tool. Logstash can collect, parse, and transform data from various sources, such as log files, databases, or message queues, and then send it to Elasticsearch. Logstash provides a rich set of plugins for different data sources and processors, making it a flexible and powerful option for data ingestion.
4. Importing Data Using Beats
Beats are a family of lightweight data shippers developed by Elastic. They are designed for specific data types, such as log files, system metrics, or network packets. Beats can be installed on the data source and configured to send data directly to Elasticsearch or Logstash for further processing. Beats are an excellent option for ingesting data from multiple sources and sending data from edge devices to a central cluster.
5. Best Practices for Data Ingestion
To optimize data ingestion performance, it’s essential to follow some best practices. Some of these are:
- Avoid sending too much data at once:
Sending large batches of data can overload the Elasticsearch cluster and cause high CPU and memory usage. It’s better to send smaller batches of data or use a backpressure mechanism to limit the rate of data ingestion. - Use suitable data types:
Elasticsearch supports many data types, such as strings, numbers, dates, and nested objects. Using the correct data type for each field can improve the performance and accuracy of the search and aggregation operations. - Create the correct mapping:
The mapping defines the structure of the documents and the settings for each field. Creating the proper mapping can improve the performance and accuracy of the search and aggregation operations.
Need help on Elasticsearch Clusters?
Our experts can help you in all kinds of works in Elasticsearch Clusters.
Conclusion
Ingesting data into Elasticsearch clusters is an essential task for any data-driven organization. By understanding the Elasticsearch data model, and the different methods available for importing data, you can ensure that your data is stored, searched, and analyzed efficiently. By following best practices for data ingestion, you can optimize the performance of your Elasticsearch cluster and ensure that your data is accurate and accessible. Elasticsearch is a powerful and flexible tool that can help you to gain insights and make data-driven decisions.
At ISmile Technologies we see DevOps as a no-touch CI/CD driven software delivery approach which believes that a single integrated delivery function from requirements to production will provide higher business value.. Schedule your free assessment today.






