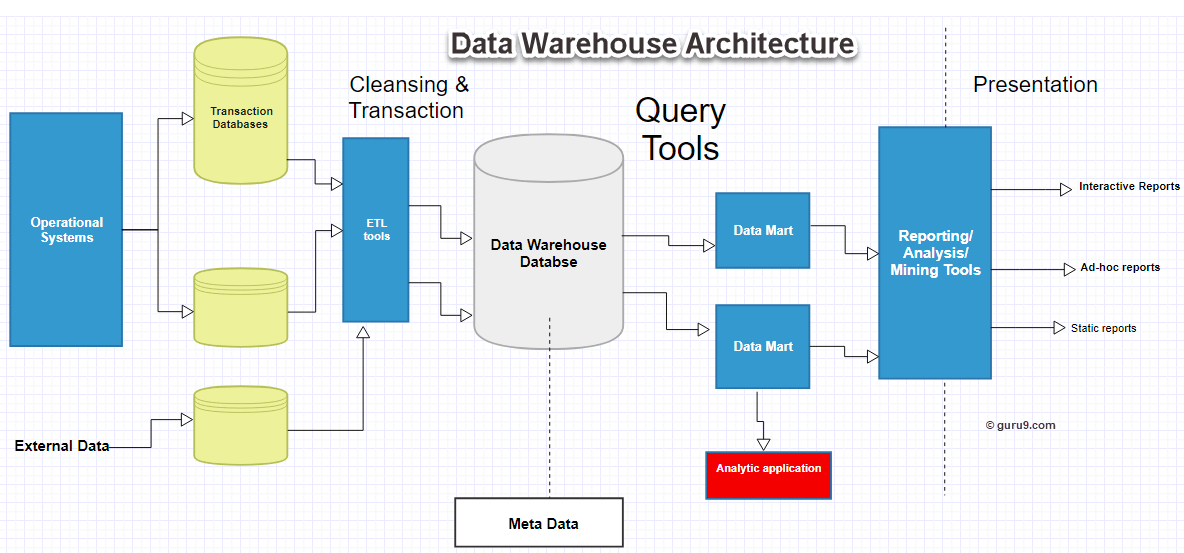

The data warehouse is the infrastructure component where data is stored in easy to query format and can be readily accessed by data scientists and analysts. It collects information from multiple sources of truth databases related to transactions within various business units and departments of an organisation. Specific set rules are formed by the organisation to validate the data quality. It is stored in denormalized format- that is storing various information together for querying. Denormalized format helps in weeding out complexities from queries by minimising the number of data joins.
Data warehouse architecting
For developing the dimensional model of data warehouse, three stages of designing process are afforded.
- Business model- This model generalises data based on the requirements of the business
- Logical model- It is used for setting the column types
- Physical model- It is used for creating the blueprint of the physical design of the data warehouse
For devising the apt model, it is required that stakeholders agree on the granularity level of data percolating from various aspects of the business. The model must be validated by the stakeholders before implementation. The structure of information storage in the form of dimensions or fact tables in the data warehouse is called the star schema. The fact table is used for recording events like sales volume, balances etc. The dimension table is used to store descriptive information of the entities in the fact tables like dates, names, locations etc. The fact table can be transactional for recording at a a set granularity, periodic for recording within a given time frame and cumulative for recording information within the business process.
Improving the speed of retrieving data
It is advisable to create clustered index for querying. This reorders the way the records are stored helping in retrieval. Creating multiple clustered indices help in keeping copies of information, irrespective of the way the tables are stored. For example, if we create clustered index for meetings date of the organisations. The fact table will be reorganised in a manner that the upcoming meetings will be shown sequentially resulting in faster retrieval.
Partitioning for performance enhancement
Splitting up large tables into smaller parts or partitioning helps in faster processing of queries that needs access to only a small amount of data. Partitioning can be either through splitting the columns (vertical) and splitting the rows(horizontal)
Optimising database size during designing
Estimating and optimising the size of database during data warehouse designing helps in fine tuning the performance. It helps aligning performance with the requirements of your applications portfolio. Moreover, it helps in devising the demand of the physical disk space and also helps in optimising the cloud storage costs. For this you need to aggregate the table sizes. If the table size is exceedingly large than desired level, you need to normalise certain aspects of the database. If the size is smaller, you need to denormalize.
Optimise your data storage
The data stored in the data warehouse can be organised in to smaller databases as per the requirements of the organisation. Create data marts for specific SBUs within the organisation. Start with first level data mart and least risky implementation and then build the foundations for enterprise-wide storage. An operational data store can also be set up for reporting purposes on operations.
Alongwith that employ a Master data management system for your core business functions.
For processing big data
For processing big data, use tools like Apache Hadoop. Hadoop allows for faster, distributed processing of large varieties of data across computer clusters. Processing streaming data becomes quick with Hadoop.
Querying data out of the warehouse
Once set, users should be able to easily access and query data out of the warehouse. For reducing the query run time, you need to tune complex queries into simpler ones and reduce the number of calculations that your software and hardware makes. For this you may be required to reduce the table size, make joins simpler, reduce the number of concurrent queries running on a database, take into account memory, disk usage considerations, write hierarchical queries , use parallelism and more.
Archived data strategy
Archived data is of high interest to data analysts looking to conduct regression using historical trends. It is advisable to relocate historical data into a separate less costly storage having high latency while ensuring high searchability



